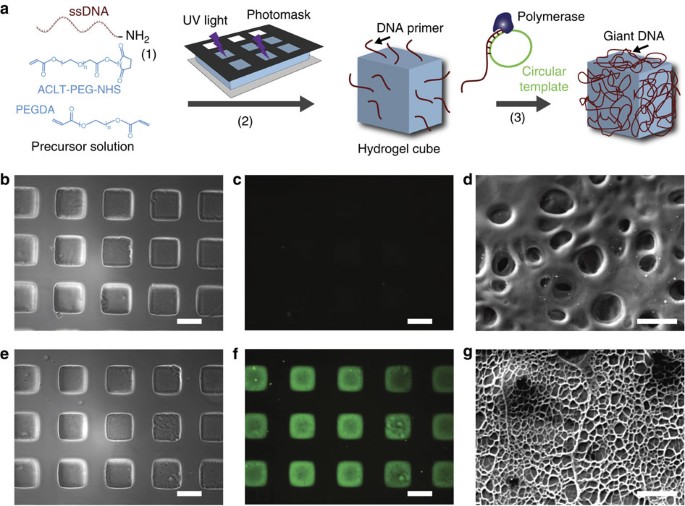
Language models might be able to self-correct biases—if you ask them
A study from AI lab Anthropic shows how simple natural-language instructions can steer large language models to produce less toxic content.

Articles by Deborah Raji

Successfully Mitigating LLM Bias: Introspection & Prompt Engineering with LLM-Genie!
Availability Heuristic - The Decision Lab

Articles by Antonio Regalado

Human-like intuitive behavior and reasoning biases emerged in large language models but disappeared in ChatGPT
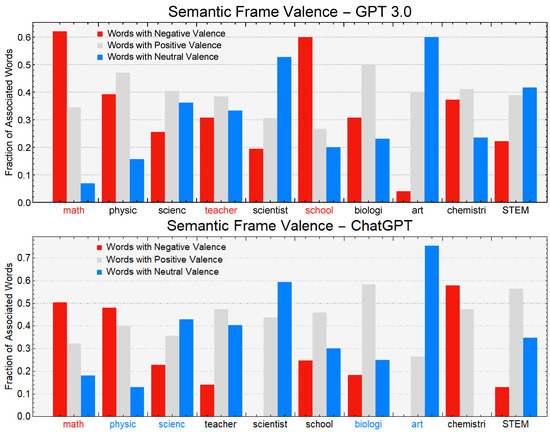
BDCC, Free Full-Text

Sutherland on LinkedIn: Language models might be able to self

8 Questions About Using AI Responsibly, Answered

Self-Correction of Biases in Language Models -Lit Review

Cognitive bias - Wikipedia

Georg Huettenegger on LinkedIn: Language models might be able to
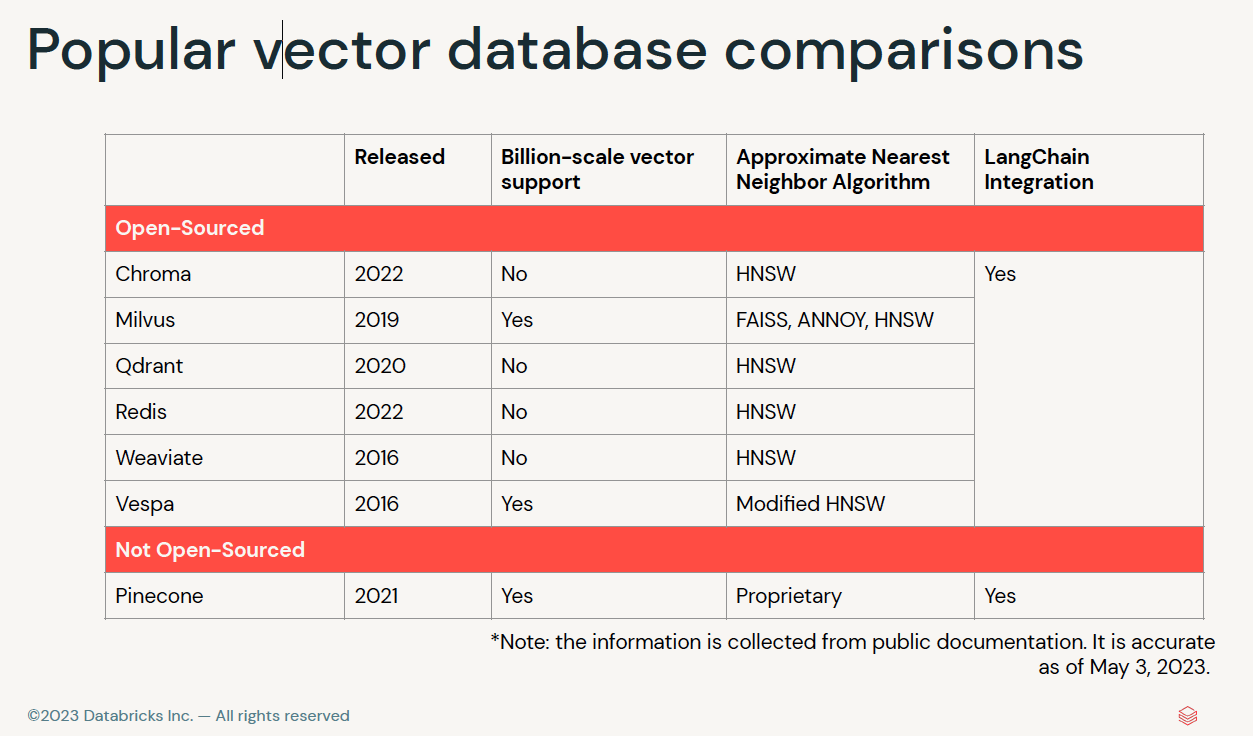
edX LLM Application through Production - ihower's Notes